
The DPE Client Library team at Google handles the release maintenance, and support of Google Cloud client libraries. Essentially, we act as the open-source maintainers of Google’s 350+ repositories on GitHub. It’s a big job…
For this work to scale, it’s been critical to automate various common tasks such as validating licenses, managing releases, and merging pull requests (PRs) once tests pass. To build our various automations, we decided to use the Node.js-based framework Probot, which simplifies the process of writing web applications that listen for Webhooks from the GitHub API. [Editor’s note: The team has deep expertise in Node.js. The co-author Benjamin Coe was the third engineer at npm, Inc, and is currently a core collaborator on Node.js.]
Along with the Probot framework, we decided to use Cloud Functions to deploy those automations, with the goal of reducing our operational overhead. We found that Cloud Functions are a great option for quickly and easily turning Node.js applications into hosted services:
- Cloud Functions can scale automatically as your user-base grows, without the need to provision and manage additional hardware.
- If you’re familiar with creating an npm module, it only takes a few additional steps to deploy it as a Cloud function; either with the gcloud CLI, or from the Google Cloud Console (see: “Your First Function: Node.js”).
- Cloud Functions integrate automatically with Google Cloud services, such as Cloud Logging and Cloud Monitoring.
- Cloud Functions can be triggered by events, from services such as Firestore, PubSub, Cloud Storage, and Cloud Tasks.
Jump forward two years, we now manage 16 automations that handle over 2 million requests from GitHub each day. And we continue to use Cloud Functions to deploy our automations. Contributors can concentrate on writing their automations, and it’s easy for us to deploy them as functions in our production environment.
Designing for serverless comes with its own set of challenges, around how you structure, deploy, and debug your applications, but we’ve found the trade-offs work for us.Throughout the rest of this article, drawing on these first-hand experiences, we outline best practices for deploying Node.js applications on Cloud Functions, with an emphasis on the following goals:
- Performance – Writing functions that serve requests quickly, and minimize cold start times.
- Observability – Writing functions that are easy to debug when exceptions do occur.
- Leveraging the platform – Understanding the constraints that Cloud Functions and Google Cloud introduce to application development, e.g., understanding regions and zones.
With these concepts under your belt, you too can reap the operational benefits of running Node.js-based applications in a serverless environment, while avoiding potential pitfalls.
Best practices for structuring your application
In this section, we discuss attributes of the Node.js runtime that are important to keep in mind when writing code intended to deploy Cloud Functions. Of most concern:
- The average package on npm has a tree of 86 transitive dependencies (see: How much do we really know about how packages behave on the npm registry?). It’s important to consider the total size of your application’s dependency tree.
- Node.js APIs are generally non-blocking by default, and these asynchronous operations can interact surprisingly with your function’s request lifecycle. Avoid unintentionally creating asynchronous work in the background of your application.
With that as the backdrop, here’s our best advice for writing Node.js code that will run in Cloud Functions.
1. Choose your dependencies wisely
Disk operations in the gVisor sandbox, which Cloud Functions run within, will likely be slower than on your laptop’s typical operating system (that’s because gVisor provides an extra layer of security on top of the operating system, at the cost of some additional latency). As such, minimizing your npm dependency tree reduces the reads necessary to bootstrap your application, improving cold start performance.
You can run the command npm ls –production to get an idea of how many dependencies your application has. Then, you can use the online tool bundlephobia.com to analyze individual dependencies, including their total byte size. You should remove any unused dependencies from your application, and favor smaller dependencies.
Equally important is being selective about the files you import from your dependencies. Take the library googleapis on npm: running require(‘googleapis’) pulls in the entire index of Google APIs, resulting in hundreds of disk read operations. Instead you can pull in just the Google APIs you’re interacting with, like so:
It’s common for libraries to allow you to pull in the methods you use selectively—be sure to check if your dependencies have similar functionality before pulling in the whole index.
2. Use ‘require-so-slow’ to analyze require-time performance
A great tool for analyzing the require-time performance of your application is require-so-slow. This tool allows you to output a timeline of your application’s require statements, which can be loaded in DevTools Timeline Viewer. As an example, let’s comparet loading the entire catalog of googleapis, versus a single required API (in this case, the SQL API):
Timeline of require(‘googleapis’):
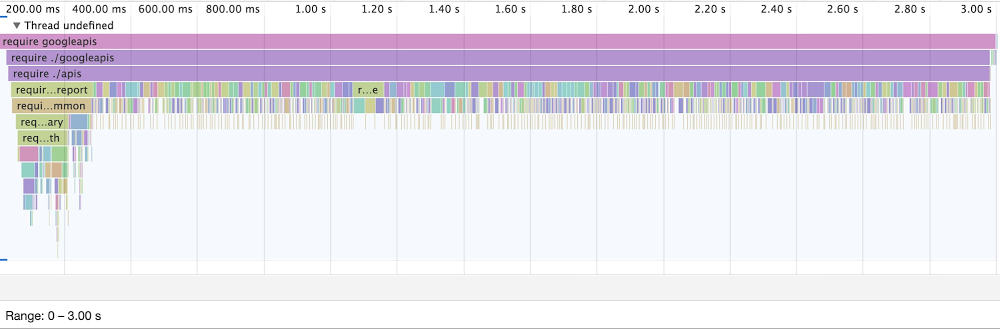
The graphic above demonstrates the total time to load the googleapis dependency. Cold start times will include the entire 3s span of the chart.
Timeline of require(‘googleapis/build/src/apis/sql’):
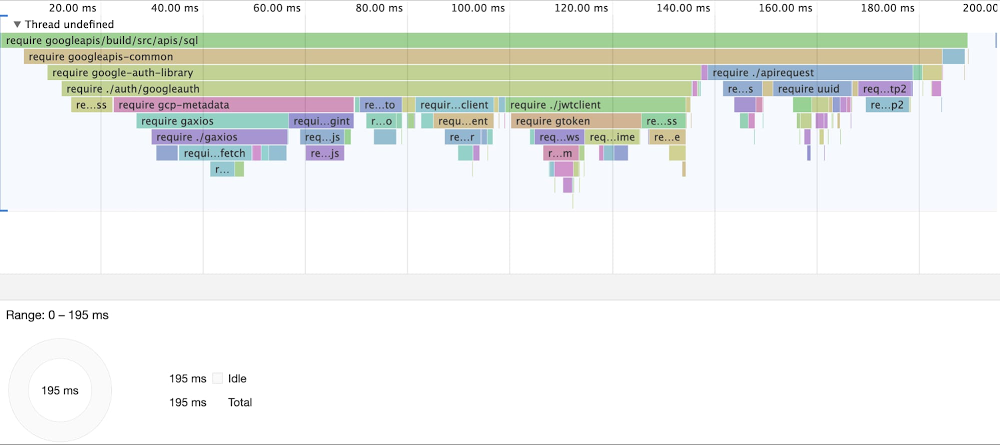
The graphic above demonstrates the total time to load just the sql submodule. The cold start time is a more respectable 195ms.
In short, requiring the SQL API directly is over 10 times faster than loading the full googleapis index!
3. Understand the request lifecycle, and avoid its pitfalls
The Cloud Functions documentation issues the following warning about execution timelines: A function has access to the resources requested (CPU and memory) only for the duration of function execution. Code run outside of the execution period is not guaranteed to execute, and it can be stopped at any time.
This problem is easy to bump into with Node.js, as many of its APIs are asynchronous by default. It’s important when structuring your application that res.send() is called only after all asynchronous work has completed.
Here’s an example of a function that would have its resources revoked unexpectedly:
In the example above, the promise created by set() will still be running when res.send() is called. It should be rewritten like this:
This code will no longer run outside the execution period because we’ve awaited set() before calling res.send().
A good way to debug this category of bug is with well-placed logging: Add debug lines following critical asynchronous steps in your application. Include timing information in these logs relative to when your function begins a request. Using Logs Explorer, you can then examine a single request and ensure that the output matches your expectation; missing log entries, or entries coming significantly later (leaking into subsequent requests) are indicative of an unhandled promise.
During cold starts, code in the global scope (at the top of your source file, outside of the handler function) will be executed outside of the context of normal function execution. You should avoid asynchronous work entirely in the global scope, e.g, fs.read(), as it will always run outside of the execution period.
4. Understand and use the global scope effectively
It’s okay to have ‘expensive’ synchronous operations, such as require statements, in the global scope. When benchmarking cold start times, we found that moving require statements to the global scope (rather than lazy-loading within your function) lead to a 500ms to 1s improvement in cold start times. This can be attributed to the fact that Cloud Functions are allocated compute resources while bootstrapping.
Also consider moving other expensive one-time synchronous operations, e.g., fs.readFileSync, into the global scope. The important thing to avoid asynchronous operations, as they will be performed outside of the execution period.
Cloud functions recycle the execution environment; this means that you can use the global scope to cache expensive one-time operations that remain constant during function invocations:
It’s critical that we await asynchronous operations before sending a response, but it’s okay to cache their response in the global scope.
5. Move expensive background operations into Cloud Tasks
A good way to improve the throughput of your Cloud function, i.e., reduce overall latency during cold starts and minimize the necessary instances during traffic spikes, is to move work outside of the request handler. Take the following application that performs several expensive database operations:
The response sent to the user does not require any information returned by our database updates. Rather than waiting for these operations to complete, we could instead use Cloud Tasks to schedule this operation in another Cloud function, and respond to the user immediately. This has the added benefit that Cloud Task queues support retry attempts, shielding your application from intermittent errors, e.g., a one-off failure writing to the database.
Here’s our prior example split into a user-facing function and a background function:
User-facing function:
Background function:
Deploying your application
The next section of this article discusses settings, such as memory, and location,that you should take into account when deploying your application.
1. Consider memory’s relationship to performance
Allocating more memory to your functions will also result in the allocation of more CPU (see: ‘’Compute Time”). For CPU-bound applications, e.g., applications that require a significant number of dependencies at start up, or that are performing computationally expensive operations (see: “ImageMagick Tutorial”), you should experiment with various instance sizes as a first step towards improving request and cold-start performance.
You should also be mindful of whether your function has a reasonable amount of available memory when running; applications that run too close to their memory limit will occasionally crash with out-of-memory errors, and may have unpredictable performance in general.
You can use the Cloud Monitoring Metrics Explorer to view the memory usage of your Cloud functions. In practice, my team found that 128Mb functions did not provide enough memory for our Node.js applications, which average 136Mb. Consequently, we moved to the 256Mb setting for our functions and stopped seeing memory issues
2. Location, location, location
The speed of light dictates that the best case for TCP/IP traffic will be ~2ms latency per 100 miles1. This means that a request between New York City and London has a minimum of 50ms of latency. You should take these constraints into account when designing your application.
If your Cloud functions are interacting with other Google Cloud services, deploy your functions in the same region as these other services. This will ensure a high-bandwidth, low-latency network connection between your Cloud function and these services (see: “Regions and Zones”).
Make sure you deploy your Cloud functions close to your users. If people using your application are in California, deploy in us-west rather than us-east; this alone can save 70ms of latency.
Debugging and analyzing your application
The next section of this article provides some recommendations for effectively debugging your application once it’s deployed.
1. Add debug logging to your application:
In a Cloud Functions environment, avoid using client libraries such as @google-cloud/logging, and @google-cloud/monitoring for telemetry. These libraries buffer writes to the backend API, which can lead to work remaining in the background after calling res.send() outside of your application’s execution period.
Cloud functions are instrumented with monitoring and logging by default, which you can access with Metrics Explorer and Logs Explorer:
For structured logging, you can simply use JSON.stringify() which Cloud Logging interprets as structured logs:
The entry payload follows the structure described here. Note the timingDelta, as discussed in “Understand the request lifecycle”—this information can help you debug whether you have any unhandled promises hanging around after res.send().
There are CPU and network costs associated with logging, so be mindful about the size of entries that you log. For example, avoid logging huge JSON payloads when you could instead log a couple of actionable fields. Consider using an environment variable to vary logging levels; default to relatively terse actional logs, with the ability to turn on verbose logging for portions of your application using util.debuglog.
Our takeaways from using Cloud Functions
Cloud Functions work wonderfully for many types of applications:
- Cloud Scheduler tasks: We have a Cloud function that checks for releases stuck in a failed state every 30 minutes.
- Pub/Sub consumers: One of our functions parses XML unit test results from a queue, and opens issues on GitHub for flaky tests.
- HTTP APIs: We use Cloud Functions to accept Webhooks from the GitHub API; for us it’s okay if requests occasionally take a few extra seconds due to cold starts.
As it stands today, though, it’s not possible to completely eliminate cold starts with Cloud Functions: instances are occasionally restarted, bursts of traffic lead to new instances being started. As such, Cloud Functions still isn’t a great fit for applications that can’t shoulder the additional seconds that cold starts occasionally add. As an example, blocking a user-facing UI update on the response from a Cloud Function is not a good idea.
We want Cloud Functions to work for these types of time-sensitive applications, and have features in the works to make this a reality:
- Allowing a minimum number of instances to be specified; this will allow you to avoid cold starts for typical traffic patterns (with new instances only being allocated when requests are made above the threshold of minimum instances).
- Performance improvements to disk operations in gVisor, the sandbox that Cloud Functions run within: A percentage of cold-start time is spent loading resources into memory from disk, which these changes will speed up.
- Publishing individual APIs from googleapis on npm. This will make it possible for people to write Cloud functions that interact with popular Google APIs, without having to pull in the entire googleapis dependency.
With all that said, it’s been a blast developing our automation framework on Cloud Functions, which, if you accept the constraints, and follow the practices outlined in this article is a great option for deploying small Node.js applications;.
Have feedback on this article? Have an idea as to how we can continue to improve Cloud Functions for your use case? Don’t hesitate to open an issue on our public issue tracker.




